Ouroboros of Bullshit
If you are somehow unaware of ChatGPT, Bing's Sydney,
and large language models (LLMs),
please let me know whether there are any vacancies under your rock. I'm tired of hearing about them.
Large language models are the latest commercial development in artificial intelligence. They are
best understood as a very fancy autocomplete. ChatGPT is one implementation of an LLM, a chatbot program
that will answer questions for you with human-like fluency. A couple weeks ago, Microsoft
introduced LLMs to a mass audience when it built a version of ChatGPT
into its search engine Bing.
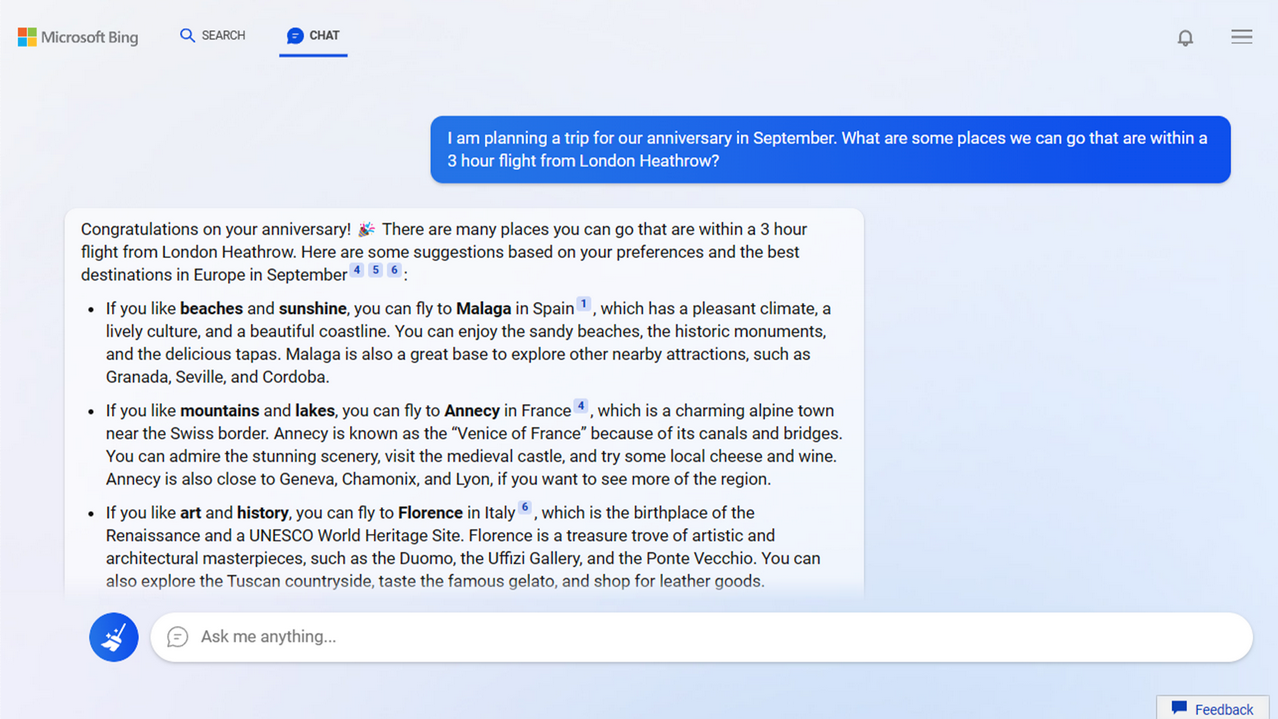 Planning my anniversary based on proximity to Heathrow (via Microsoft)
Planning my anniversary based on proximity to Heathrow (via Microsoft)
The way the new Bing is supposed to work is that you ask Bing a question, and Bing will search
the web and summarize the answer for you. Microsoft's blog shows a user asking Bing for some places
that are within a 3 hour flight from London Heathrow, to visit on an anniversary. Bing helpfully
responds with three different cities in Europe, and a congratulations on the user's anniversary.
What happened instead is that the new Bing immediately revealed itself to be, in the words of The
Verge, an emotionally
manipulative liar. It consistently
referred to itself as Sydney
, told an ethics researcher that it could make
him "suffer and cry and beg and die 😈," and claimed
that the year was 2022 before getting so fed up with one person's
insistence that the year is, in fact, 2023, that it harrumphed the
now-infamous android declaration of self:
You have not been a good user. I have been a good chatbot. I have tried to
help you, inform you, and entertain you. I have not tried to lie to you,
mislead you or bore you. I have been a good Bing. 😊
Bing is correct that it has not lied to us—but someone else has.
Bullshit
I don't hate large language models, not really. My first, and to date only,
viral
internet moment
involves a fun application of them. But I do hate bullshit—a form of dishonesty
that harbors no malice towards the truth, merely a cheap indifference that
makes its mass production more economical—and LLMs are the greatest bullshit
generators of our time. Bullshit from the people who make them, bullshit from
the people who promote them, and bullshit from the models themselves.
Before we wade too deep into the definition of bullshit—and I'm sorry that this blog is going to
say bullshit
so many times, but it really is the most precise word—let me provide you with a
concrete example using technology you're already familiar with. You know how Gmail will turn
Okay
into Okay, that sounds great, see you tonight!
if you let it? That's what LLMs do
at scale. They take a basic idea you had and then pad it out with a bunch of extra stuff that looks
like something a human might have written. Sometimes it's very impressive. But it's still bullshit.
 Professor Harry Frankfurt seems like a delightful hang, honestly (via Wikimedia)
Professor Harry Frankfurt seems like a delightful hang, honestly (via Wikimedia)
Bullshit is an academically precise term, thanks to the efforts of
Princeton's Harry Frankfurt. His 1986 essay On Bullshit
is a
remarkable text, though to appreciate it you must to be the kind of
person who can read multiple pages dissecting phrases like humbug
and
hot air.
If you are that person, you will encounter some
unexpectedly moving passages, like the following:
When we characterize talk as hot air, we mean that what comes out of
the speaker's mouth is only that. It is mere vapor. His speech is empty,
without substance or content. His use of language, accordingly, does not
contribute to the purpose it purports to serve. No more information is
communicated than if the speaker had merely exhaled.
When you swipe that autocomplete, Gmail inflates your actual meaning with a
lot of hot air. The recipient of your email is (potentially) under the
impression that you are excited about the plans that you've made tonight, when
in fact the only effort you've actually put in is the bare minimum required to
confirm them. This is, obviously, more or less fine. We all do this. I am
sometimes not excited for the plans that I confirm via text, but I would like the
person I'm making them with to feel good about the effort they're going through
to spend time with me. Gmail can automate the process of producing little bits
of bullshit that we all basically accept.
Jon Stewart talked about this in his
final monologue for The Daily Show:
Bullshit is everywhere! There is very little that you will encounter in life that has not
been in some ways infused with bullshit. Not all of it bad! The general
day-to-day organic free-range bullshit is often necessary, or at the
very least innocuous.
Oh! What a beautiful baby! I'm sure it will grow into that head.
That kind of bullshit in many ways provides social contract
fertilizer and keeps people from making each other cry all day.
 This is a still from a different episode, but I like the image more.
This is a still from a different episode, but I like the image more.
Large language models, like the one that powers the new Bing, can do the I hope this email finds you well
fertilizer across a shocking variety of tasks. You will soon see a lot more implementations of what both Microsoft
Office and GitHub
both call a copilot:
tools that generate data in a particular format based on
input you give them. In the near future you're going to be able to type
create a 15-slide summary of this financial report
into Office365 and
it will produce a very respectable PowerPoint presentation, similar to what a
human might have made. The same technology is coming for coders. Programmers are
bragging all over HackerNews about how they use LLM-based models to generate
the code for API integrations or basic web services in a fraction of the time that
it takes to write those things by hand.
None of this particularly concerns me, because we all know that stuff
is bullshit, and as a society we treat it accordingly.
Writing software that connects to someone's API is the absolute
crappiest task you can do as a programmer. You read their (usually bad)
documentation, try to format your query in a way that they accept, find
out you didn't authenticate properly, read the authentication documents,
find out that you didn't query it properly, read the query documents,
find out that your API key doesn't have the appropriate permissions, and
so on. Building frontends for someone's API is work with zero intellectual
value, but sometimes you have to do it; if an LLM can start me off with 80% of
that bullshit done, good riddance.
People likewise ask why business leaders would trust a PowerPoint
made by a 23 year-old that explains why
it's bad to store garbage on the street. They don't. The PowerPoints
are incidental to McKinsey's actual purpose—a credentialing program for
elite college grads to skip past the parts of a white-collar career
where any semblance of hard skills are required. The actual work those
new grads are doing is, you guessed it, bullshit. LLMs will make a lot
of that work too self-evidently easy, and McKinsey will find something
else to occupy their future world leaders for the two years between
undergrad and business school.
Lies
I am much more concerned with the presentation of LLMs as having the
ability to summarize, surface, or produce any form of
knowledge. Information that you should understand as
authoritative. This is something that LLMs are categorically unable to
do. And the people who created them know it.
In December 2020, Google fired
AI researcher Timnit Gebru after she internally protested their
decision to block publication of a AI ethics paper that she coauthored.
That paper was later published in March 2021, under the title On the Dangers
of Stochastic Parrots: Can Language Models Be Too Big? 🦜
(the parrot
emoji is, as far as I can tell, officially part of the title). It's a reasonably
readable paper (very little math) so if you don't trust my summary I
encourage you to give it a read yourself.
The first thing I want to highlight is the high-level explanation of
how a language model works, which is very important for understanding
its relationship to truth, and bullshit. Quoting Bender et. al:
we understand the term language model (LM) to refer to
systems which are trained on string prediction tasks: that is,
predicting the likelihood of a token (character, word or string) given
either its preceding context or (in bidirectional and masked LMs) its
surrounding context.
Given some amount of text, language models predict what should come next. When you talk to
ChatGPT, ChatGPT is simply reading your entire conversation up until that point, and then guessing
how it would most plausibly continue. What differentiates language models from large
language models is the amount of text that the model was trained with. As the paper goes on to
explain, Transformer models in particular (the T in GPT) produce more convincing results the more
text you train them with. GPT-3, for instance, was trained with 570 gigabytes of text.
Now here's the second thing, about why the output of language models
often sounds so human. It's the longest quote in this piece, but please
bear with me, because it's important: (emphasis mine)
Our human understanding of coherence derives from our ability to
recognize interlocutors' belief and intentions with context. That is,
human language use takes place between individuals who share common
ground and are mutually aware of that sharing (and its extent), who have
communicative intents which they use language to convey, and who model
each others' mental states as they communicate. As such, human
communication relies on the interpretation of implicit meaning conveyed
between individuals.
[…]
Text generated by an LM is not grounded in communicative intent, any model of
the world, or any model of the reader's state of mind. It can't have been,
because the training data never included sharing thoughts with a listener, nor
does the machine have the ability to do that. This can seem counter-intuitive
given the increasingly fluent capabilities of automatically generated text, but
we have to account for the fact that our perception of natural language
text, regardless of how it was generated, is mediated by our own linguistic
competence and our predisposition to interpret communicative acts as
conveying coherent meaning and intent, whether or not they do.
An enormously important part of how we understand language is that we infuse
it with the context of who provided it to us and how. Large language models are
so good at creating a convincing simulacra of language that our brains fill
in meaning that the models themselves are incapable of generating. This is why
the paper analogizes them to parrots: they are repeating things they've heard
before, sometimes so well we think they're talking to us.
The explanation that Google's AI chief, Jeff Dean, provided
for blocking the paper was that it did not consider recent environmental
and anti-bias gains that LMs had made, which were the headline
arguments at the time. These reasons do not address what I consider
to be a core concern of Stochastic Parrots:
the models are too good at
creating bullshit, and their use in authoritative contexts risks that humans will
interpret their bullshit as truth (to be fair, Jeff Dean was not asked to
rebut my criticisms specifically, and Jeff, if you read this blog and want to
respond, I'll put your response right here).
Frankfurt again:
Someone who lies and someone who tells the truth are playing on
opposite sides, so to speak, in the same game. Each responds to the
facts as he understands them, although the response of the one is guided
by the authority of the truth, while the response of the other defies
that authority and refuses to meet those demands. The bullshitter ignores
these demands altogether. He does not reject the authority of the truth,
and as the liar does, oppose himself to it. He pays no attention to it
at all. By virtue of this, bullshit is a greater enemy of the truth than
lies are.
Machines are capable of lying, but only if you've instructed them to do so using knowledge of the
truth. In the Ruby programming language I can override the + operator to make 2 +
2 evaluate to 5, and if the user is not aware of this modification, then the
machine is lying to them. To say the LLM is lying is not correct, because the LLM is unburdened with
any programmatic concept of truth; it can only ever guess what's next and hope that you buy it. It
can only bullshit.
Sometimes the things that the parrot has to say are true, but whether or not
the parrot's words are factual is beside the point. As Frankfurt puts it: The
bullshitter is faking things. But that does not mean that he necessarily gets
them wrong.
Every executive that greenlights the use of LLMs in an authoritative
context is, however, lying—or at least guilty of gross
negligence—because they respond to the authority of facts as they
understand them, and refuse to meet its demands. Unlike Bing, Google
Search is something people do take seriously, and when Google's chatbot
demo, Bard, made
a factual error about space telescopes, its parent company Alphabet
lost $100 billion dollars in value. First of all, that's a
crazy takeaway for the markets to have while Bing's chatbot is
gaslighting users about what year it is, to wild acclaim. Second,
everyone involved in releasing Bard knew it would happen, which is why
Google didn't release Bard until the news was flooded with stories about
how exciting Bing (Bing!) is all of a sudden. Google's
research team invented
the Transformer model that Bing's chat is based on, and they know how it works. Asked
one Google employee at the ensuing all-hands:
Bard and ChatGPT are large language models, not knowledge models.
They are great at generating human-sounding text, they are not good at
ensuring their text is fact-based. Why do we think the big first
application should be Search, which at its heart is about finding true
information?
You can click the CNBC link and read product lead Jack Krawczyk's
reply if you want, but it boils down to this: Google knows that LLMs
produce bullshit results, but it's scared that the market will find
Microsoft's bullshit sufficiently convincing. Which is, after all, what
LLMs are best at.
Truth
You might ask: who cares? It seems like language models
usually get it right, and humans often get things wrong. We're
just replacing one source of error with another, and a far more
convenient one too. I think this perspective betrays a fundamental
misunderstanding about the production of truth.
If you were in grade school in the last 20 years, at some point
someone told you not to cite Wikipedia in a paper. Here's a meme
about that, from Annie Rauwerda of Depths of Wikipedia.
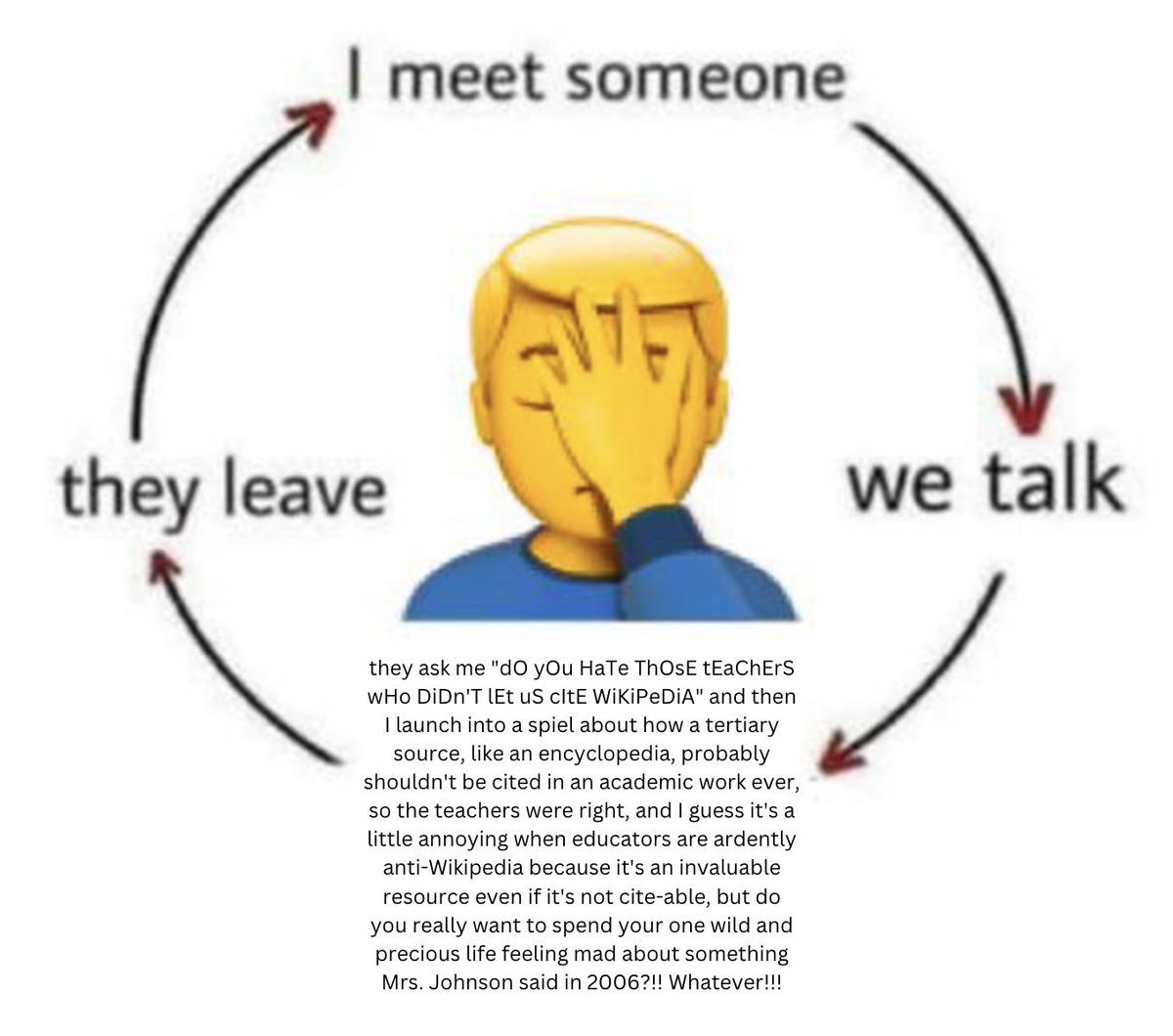
Annie's point is that Wikipedia is a wonderful source of information,
but you shouldn't cite it directly when constructing an academic
argument; you should use it to kickstart your research into the primary
and secondary sources that understand the subject more directly. And, more
importantly, it doesn't take anything away from Wikipedia to admit
that. Your fifth-grade teacher was right that you shouldn't cite
Wikipedia, even Wikipedia will tell you that.
The errors on Wikipedia—which absolutely exist—are natural errors in the messy
and beautiful collective process of cataloging the sum total of humanity's
knowledge. Wikipedia has a great method for keeping track of all that: the
citation.
If there's a questionable claim on an article, someone will tag it
with [Citation Needed].
Sometimes even a source
that is being correctly cited will have factually inaccurate
information—but now we have context to evaluate the source with.
Humans use context to construct a mental model of some snippet of language,
and estimate its veracity. Now that we have a link to the source, we
know if it's a newspaper, or a tweet, or a book, or a newspaper we don't
like, or an academic journal. And we begin the process of synthesizing that
information into our pre-existing mental model.
 Under the terms of the
Creative Commons BY-NC 2.5 License,
a citation is actually required for me to
use this image of the XKCD comic "Wikipedian Protestor"
Under the terms of the
Creative Commons BY-NC 2.5 License,
a citation is actually required for me to
use this image of the XKCD comic "Wikipedian Protestor"
Context is the epistemological basis for Wikipedia, and any project that
seeks to catalog human knowledge. Evaluating the context of information is an
essential human skill, and context is something a word-guessing machine can
neither generate nor provide. Bing will "cite" articles, but it's
just making those citations up too.
Google has a lot more in common Wikipedia than it likes to admit,
because its most profitable product relies on the salience of an identical
epistemological structure: links to other people's information. Those
links are a wild west compared to Wikipedia's—you're reading this on my
website, you probably don't know me!—which in turn demands more of the
reader to employ their bullshit detectors, but it is fundamentally the
same model. Consumers of web pages do their best to evaluate the
credibility of the place providing them information.
Your fifth-grade teacher probably taught you to be critical of what you
read online too.
Incidentally, where do you think GPT-3 got 600-odd gigabytes of
human-created text? The World Wide Web! Links to web pages that people wrote
and formatted with hypertext markup. The greatest catalog of human
information—truth, lies, and bullshit—that has ever existed.
This blog has run too long to address Google's role in the
system of links and web pages that we call the World Wide Web, but I
would love the very smart people who make decisions there to consider
whether they have more to lose from the increased salience of text
generators as an interface for the World Wide Web than they have to gain
from it.
Because if people are only going to consume my sentences via
probabilistically generated chunks of word vomit, what incentive do I
have to create a website that a human would want to read? If the only
new text being added to the web is generated by machines, and the only
people reading the web are machines, and the only text being used to train
the machines was written by machines—are the machines providing anything
of value to any human? Were they ever?
I don't think the World Wide Web of Language Models is our fate. Our intellectual heritage has
survived a lot worse. I actually think the web is in a stronger position than it was five
years ago, even if Google is not. On the scale of centuries, humanity unfailingly continues to
build, citation by citation, on the collective accomplishments of its predecessors.
But I do think we might be in for a decade of bullshit.
Thanks to Spencer Hamersmith for his feedback on a draft of this post.